Measuring misinformation and collecting data from online social networks
Infodemics Pandemics Summer School, August 28th, 2023
Graz University of Technology | Complexity Science Hub Vienna
Jana Lasser | jana.lasser@tugraz.at | @janalasser
Motivation
Infodemics Pandemics Summer School
Infodemics Pandemics Summer School
Some estimates from Canada: If those who reported believing COVID-19 is a hoax were vaccinated when they became eligible...
... over 2.3 million additional people would have been vaccinated,
... resulting in roughly 198,000 fewer cases,
... 13,000 fewer hospitalizations, and
... 2,800 fewer deaths from COVID-19 between March 1 and November 30, 2021.
... The cost of hospitalizations (including ICU) of these cases is estimated at $300 mio.
How can we measure the "infodemics" part?
Council of Canadian Academies, Expert Panel on the Socioeconomic Impacts of Science and Health Misinformation, "Fault lines" (2023).
Outline
Defining misinformation
Measuring misinformation
Using social media data to study misinformation
Defining
misinformation
Dimensions of misinformation










Misinformation: false or misleading content shared without malicious intent.
Disinformation: false or fabricated content shared with the intent to mislead or cause harm.
False or fake news: news-like content that is verifiably false. Can include deep fakes and cheap fakes.
Systematic lies: Carefully constructed fabrications or obfuscations (e.g. weapons of mass destruction in Irak).
Malinforation:
true information shared to cause harm, for example hate speech or private information.
Propaganda: information, especially of a biased or misleading nature, used to promote a political cause or point of view. Can be political or industrial.
Satire & parody: content indended to be funny that doesn't make an attempt to be perceived as true.
Conspiracy theories:
Alternative explanations for traditional news events which assume that these events are controlled by a secret elite group.
Wardle et al., Information disorder: Toward an interdisciplinary framework for research and policymaking (2017).
Lewandowsky, et al., Technology and democracy: Understanding the influence of online technologies on political behaviour and decision-making (2020).
Measuring
misinformation
What is "factual"?
A way to define what is fact is the current consensus opinion of experts.
Who are experts and what is consensus?
Examples:
(1) Early WHO advice on masking during COVID-19
(2) The dispute over the origin of SARS-CoV-2
(3) Weapons of mass destruction in Irak

What is deceptive?
Measuring intent is already hard in experiments. How to determine intent in a piece of information?

Signals we can use to identify misinformation
Information content (quality of evidence?)
Is the information in the post or news article factual?
What style is it written in?
Interactions with the information (consensus?)
How do people react to the information?
Information source (experts?)
Which organisation or individual communicated the information?
Detecting misinformation at scale: machine learning
Using machine learning to detect misinformation assumes that factuality and deceptiveness leave context-independent patterns in text that can be detected.
Alternatives?
Observation: Much of the information eco-system on social media platforms is driven by news-like content.
Observation: News-like content comes from a limited number of news outlets.
Idea: focus on the process that generated the information and the trustworthiness of the source instead of the information itself.
From factuality to source trustworthiness
Sources are rated by journalists, fact checkers and academics according to journalistic & transparency criteria.
Source trustworthiness assessments oftentimes also differentiates two dimensions: trustworthiness & political bias.
Currently this is a frequently followed approach in the literature, e.g.
Grinberg et al., "Fake news on Twitter during the 2016 US presidential election", Science (2019).
Pennycook et al., "Shifting attention to accuracy can reduce misinformation online", Nature (2021).
Lasser et al., "Social media sharing of low quality news sources by political elites", PNAS nexus (2022).
Assessing source trustworthiness at scale
(1) Create a closed list of news outlets (domains, e.g. "spiegel.de") selected via popularity (webtraffic).
(2) Assess news outlets according to journalistic standars (and ideological bias) following a list of criteria, e.g.:
Does the news outlet differentiate between "news" and "opinion"?
Does the news outlet have a process for correcting mistakes?
Does the news outlet disclose the identities of owners and article authors?
...
(3) Extract links from social media posts and compare the domains with the list of rated domains.
Assessing source trustworthiness at scale
✅ Create a closed list of news outlets (domains, e.g. "spiegel.de") selected via popularity (webtraffic).
✅ Assess news outlets according to journalistic standars (and bias) following a list of criteria, e.g.:
Does the news outlet differentiate between "news" and "opinion"?
Does the news outlet have a process for correcting mistakes?
Does the news outlet disclose names of owners and article authors?
...
(3) Extract links from social media posts and compare the domains with the list of rated domains.
Data bases of news outlet trustworthiness
NewsGuard
- By journalists, large list, N entries: English 9515, Italian 516, French 452, German 368.
- Sources ranked along 9 critera for 100 points total, <60 points = "not trustworthy".
- Expensive: ~10k€ / year, regularly updated.

Compilation of existing academic & fact-checking lists + imputation with NewsGuard by Lin et al. (preprint):
- Consolidates ratings across lists following ensemble "wisdom of experts" approach.
- Largest list, N entries: 11,520, freely available.
Trustworthiness of information shared by politicians

Lasser et al., "Social media sharing of low quality news sources by political elites", PNAS nexus (2022).
Limitations
(-) Misses everything that doesn't contain a link
(-) Link shorteners are an issue
(-) Strong focus on (US) English language sources
(-) Constant struggle to update (NewsGuard helps)
(-) NewsGuard is very expensive (Lin et al. helps)
(-) Biased rating criteria?

Correlations between different lists

Lin et al., "High level of correspondence across different news domain quality rating sets", PNAS nexus, accepted (2023).
Using social media data
to study misinformation
The role of social media in information sharing
% of US adults who say they ever use ...
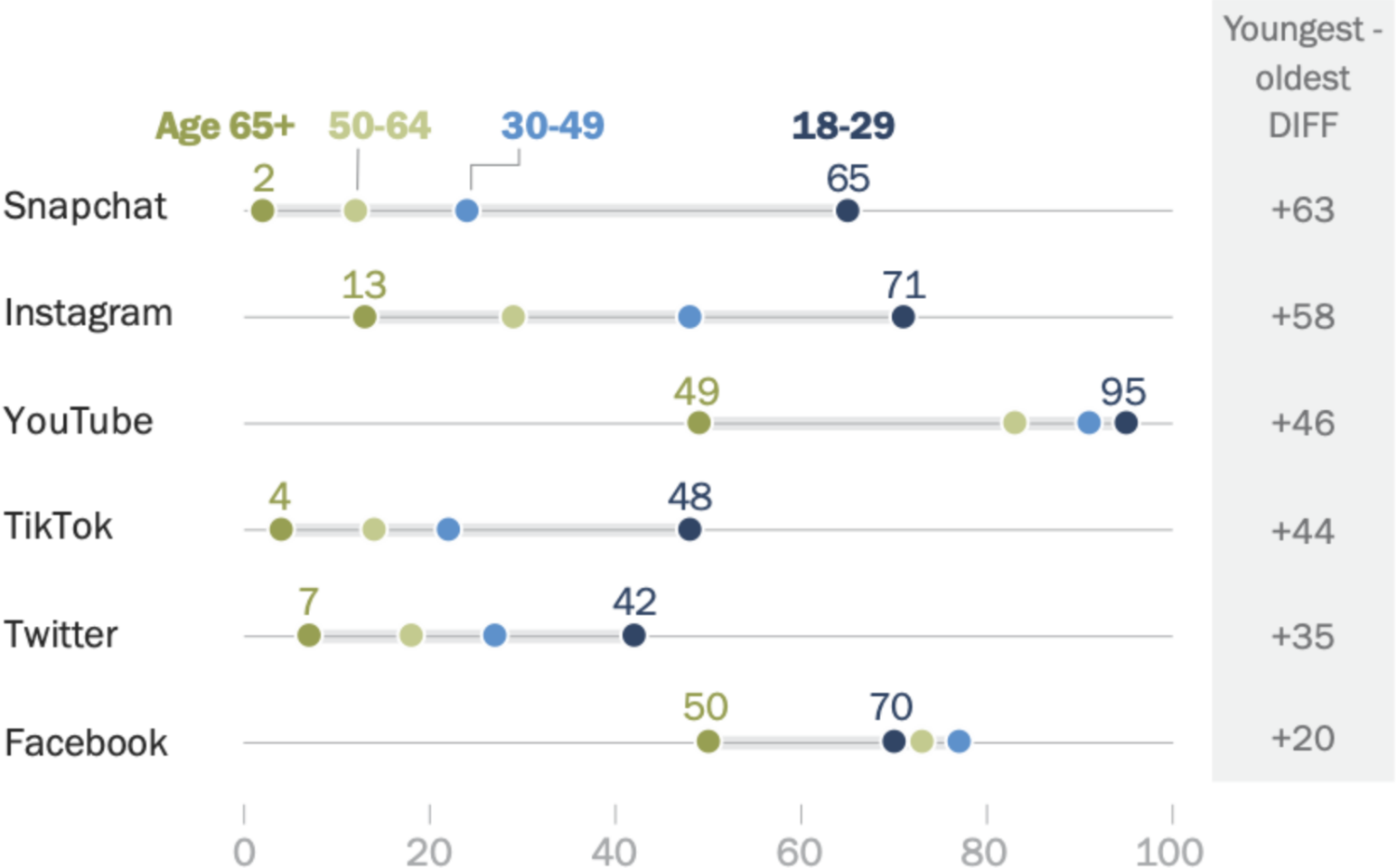
Source: Brooke Auxier and Monica Anderson, Pew Research Center, 2021.
Many people use
social media
Social media
users are not
representative ...
... but social media as a whole is – to some extent

Source: Garcia et al., "Social media emotion macroscopes reflect emotional experiences in society at large" arXiv:2107.13236 (2021).
Digital traces
When using social media platforms, people leave digital traces.
Digital traces allow us to directly observe behaviour.
Digital traces are not created with research as primary purpose.
See also lectures "Representation in Digital Traces" and "Measurement Issues of Digital Traces".

How to get the data: API interlude

"API" stands for application programming interface.
How to get the data: API interlude

"API" stands for application programming interface.
How to get the data: API interlude

"API" stands for application programming interface.
Endpoints
An API endpoint is the end of your communication channel to the API.
An API can have different endpoints for channels leading to different resources.
Example: New York Times API

(-) /archive: get NYT article metadata for a given month.
(-) /search: search for NYT articles with filters.
(-) /books: Get the NYT best sellers list and lookup book reviews.
(-) /mostpolular: Get popular articles on NYTimes.com.
Anatomy of an API request
Using the command line tool curl.

Anatomy of an API response
Very often, API responses are formatted as JSON objects.
{
"response":{
"docs":
[
{
"abstract":"Judge Noreika was appointed by President Donald J. Trump, but had the support ...",
"web_url":"https://www.nytimes.com/2023/07/26/us/politics/hunter-biden-case-judge.html",
"lead_paragraph":"The federal judge presiding over the Justice Department’s case against Hunter ..."
},
...
]
}
}
Wrappers
Writing requests manually is tedious.
Wrappers add a layer of abstraction that makes this job easier for us.
# Example: interacting with the NYT API through pynytimes
from pynytimes import NYTAPI
from datetime import datetime
NYT_client = NYTAPI(API_key, parse_dates=True)
articles = client.article_search(
query = "Biden",
results = 30,
dates = {
"begin": datetime(2023, 8, 1),
"end": datetime(2023, 8, 27)
}
)
Rate limits & quotas
Rate limiting is a strategy for limiting network traffic. It puts a cap on how often we can send requests to an API before being temporarily blocked.
Quotas limit how much data we can download in a given time frame.
Example: New York Times API
(-) 5 requests / minute
(-) 500 requests / day
(-) No quota
Pro tip: if you are planning a massive data collection project: check out the rate limits right away.
The data situation
We might be entering a "dark age" of social media data access.
Meta: no general access to Facebook &
Instagram data after Cambridge Analytica.
Twitter: academic access shut down. New
enterprise API might cost 42,000$ / month.
Reddit: Pushshift API shutdown after Reddit
introduced API pricing.
TikTok: the API's Terms of Service make it
almost impossible to use for research.

Source: https://www.medievalists.net
Alternative: the Telegram API
What do you get? Messages & media in a given group or channel, interactions with posts.
Usefulness: Data from fringe-groups that are not represented on big social media platforms. Still severly underused in CSS research.
Accessibility: API lacks documentation, python wrapper not really designed for data collection, data collection at scale requires SIM cards, snowball sampling.
Example publication: What they do in the shadows: examining the far-right networks on Telegram.
Alternative: the Mastodon API
What do you get? Toots (search with query language), account timelines, account follows, ....
Usefulness: Good data coverage, still low number of users (~2 mio active).
Accessibility: Well documented, accessible & free API, python & R wrappers. Rate limit default: 300 requests / 5 minutes.
Example publication: Exploring Platform Migration Patterns between Twitter and Mastodon: A User Behavior Study.
Alternative: Facebook & Instagram via CrowdTangle
What do you get? Public posts and reactions.
Facebook: pages >25K Followers, groups >95K members, US-based groups >2K members, verified profiles (total: ~7M).
Instagram: >50K followers, verified accounts (total: ~2M).
Usefulness: No "normal" users, still useful to monitor the conversation.
Accessibility: CrowdTangle API requires application, no real rate limit.
Example publication: How Vaccination Rumours Spread Online: Tracing the Dissemination of Information Regarding Adverse Events of COVID-19 Vaccines.
Working with existing data sets
Reddit: Pushshift data set: coverage from June 2005 to April 2023.
Twitter: 1% sample data set, full 1-day data set(s), COVID stream data set, ...
Telegram: Pushshift data set (27k channels, 2015-2019, seed: right wing & crypto currency), "Schwurbelarchiv" data set (9k German channels, 2020-2022, conspiracy theories)
Facebook: Social Science One link data set (requires application).
Misc: Social Media Archive (Twitter, Facebook, Youtube, Instagram, Reddit), LOCO corpus of conspiracy theories (websites).
Web scraping

Source: @saraduit
What is webscraping?

List of United States presidential Elections page source
How does it work?
Write code that sends a request to the server hosting the web page.
In Python the "requests" package helps to send and receive requests.
import requests
page = "https://forecast.weather.gov/MapClick.php?lat=37.7772&lon=-122.4168"
page = requests.get(page)
How does it work?
The server sends the source code of the webpage: (mostly) HTML.
Web browsers render the HTML code to display a nice-looking website.
We need to parse the information to identify elements of interest.
Scraping Twitter data
ScrapFly seems to work even after login requirement from June 30.
Twitter's robots.txt currently disallows all scraping!

A word of caution:
July 3: Cease and desit letter to Meta explicitly mentions unlawful scraping.
July 14: Twitter sues four unknown entities for unlawful data scraping.
August 1: Twitter sues hate-speech watchdog.
Outlook: the Digital Services Act
"Upon a reasoned request [...], providers of very large online platforms or of very large online search engines shall, within a reasonable period, as specified in the request, provide access to data to vetted researchers [...] for the sole purpose of conducting research that contributes to the detection, identification and understanding of systemic risks in the Union."
Article 40, Data access and scrutiny - the Digital Services Act (DSA).
The Digital Services Act came into force on August 25, 2023.
Summary
(1) Defining misinformation
Dimensions "facticity" and "deceptiveness".
Distinction between misinformation, disinformation and malinformation.
(2) Measuring misinformation
From factuality & deceptiveness to trustworthiness & bias.
Assessing source trustworthiness is current standard. Free source lists exist.
(3) Getting data from social media
Getting new data is hard, Facebook, Twitter and Reddit APIs are dead.
Telegram, Mastodon, CrowdTangle and historic data sets are alternatives.
Materials
| Resource | Link | Publication |
|---|---|---|
| News outlet trustworthiness list | list as CSV | Lin et al., High level of correspondence across different news domain quality rating sets, PNAS nexus, accepted, preprint (2023). |
| API access code snippets (Python) | Jupyter Notebook | - |
| Web scraping code snippets (Python) | Jupyter Notebook | - |
| SEIRX dynamics in a school (Python) | code & data | Lasser et al., Assessing the impact of SARS-CoV-2 prevention measures in schools by means of agent-based simulations calibrated to cluster tracing data, Nat. Comm. (2022). |
| SEIRX dynamics in a nursing home (Python) | code & data | Lasser et al., Agent-based simulations for protecting nursing homes with prevention and vaccination strategies, J. Royal Soc. Interface (2022). |